
Abstract
As the information age changes the world around us, humans are interacting with ever-increasing amounts of data. While it can be difficult to remember details from data, presenting it in a coordinated manner can aid in its retention and recall. In this work, we investigate whether placing a greater degree of emphasis on elements of coordination in a multi-channel presentation system aids in recall of information. The interface described in this paper presents three coordinated channels of information: a pair of interactive time-series graphs, a text narrative and its vocalization, and salient external search data. 36 subjects were asked to use the interface to explore stock market data in one of two groups. For subjects in the increased-emphasis group, the interface color-coordinates related data across visual elements to emphasize the coordination between channels of information. Subjects in the control group received the same interface with no color coordination. It was hypothesized that increasing emphasis on coordination would produce a positive effect on recall of information from the interface. Subjects in the increased-emphasis group exhibited significantly greater accuracy than the control group when attempting to recall dates, but only for graph patterns presented with more detailed descriptions. However, subjects in both groups exhibited significantly worse accuracy when attempting to recall graph patterns that were presented with more detailed descriptions than those presented with simpler ones. Thus, increasing emphasis on coordination only helped accuracy of recall for dates, and only when the patterns associated with those dates were more difficult to recall to begin with.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Data is constantly being collected around us. Data is collected in increasing amounts when we make purchases, visit the doctor, or browse the internet. However, data is rarely collected without purpose; there is usually the expectation that someone will eventually examine it. As more data is collected, less skilled people find themselves in the position of examining it. Difficulties are also encountered by those learning new subjects or doing individual research. Much of the data that is encountered will not be relevant, and much of the relevant data will not be easy to identify. Remembering the relevant details and/or relocating their positions in the data can be difficult, and those with little experience may not be able to overcome these challenges.
These challenges are not exclusive to digital data; they present themselves with physical data as well. Humans have developed strategies for coordinating detailed physical data. It is common to see students use colored highlights to draw their attention to specific passages of text. If similar approaches are applied to digital data, would they provide similar benefits?
Multi-modal information presentation has proven itself as an effective method of human communication across various applications [1, 2]. Instructional environments [3] and domain-specific decision making [4] have utilized coordinated multi-channel, or multi-source, data presentation. It has also been shown to aid in learning and comprehension [5] with paired textual/verbal [6] and textual/visual sources [7, 8]. Successfully presenting multiple channels of information requires them to be coordinated. It is thought that this coordination may help offset the cognitive load of engaging with additional information [3].
In this work, we investigate whether increasing the degree of emphasis on coordination in a multi-channel data presentation system increases memory of information. The system described in this paper presents users with stock market data via three coordinated channels of information: visualizations of time series data, a textual and vocalized description of patterns in the data, and salient external data. Channels are mainly coordinated using critical points, which are dates of significant changes in graph trends which appear throughout the data. Critical points define stock patterns, are referenced by the narrative, and define the search parameters for salient data search. We hypothesize that increasing the degree of emphasis on data coordination between channels will help individuals remember information more accurately from each channel. To investigate this hypothesis, a human subject study was performed. Subjects were asked to explore stock market data using a version of our interactive interface with either increased emphasis on coordination between channels or not. Afterward, they were quizzed on details of the information that they explored. While subjects in both groups showed significantly worse recall for patterns presented with more complex descriptions, subjects in the increased-emphasis group showed significant improvement over the control group for recall of specific dates associated with those patterns.
2 Related Work
The system and experiment for coordinated multi-channel information presentation described in this paper draws mainly from three sources of information. Our usage of explicitly linked and redundant information is motivated by experimental work on the presentation of multiple types and modes of information in learning scenarios. Our use of narrative, and method for narrative generation, build off of previous work in narrative systems with coordinated information presentations, and literature on the memorability of narrative. Our method for graph pattern recognition is based largely off of existing work on automated stock pattern recognition.
2.1 Learning and Multi-channel Information Presentation
Presenting multiple channels of information has been shown to help individuals learn and retain information [1, 2]. However, there exists an apparent contradiction. Presenting more channels of information in parallel splits attentional resources and demands an increase in information processing commensurate with each additional channel. According to models of working memory, splitting and increasing an individual’s commitment of cognitive resources should hinder rather than help learning of information [9].

Moreno & Mayer’s model for learning in multimedia learning environments [3].
Moreno & Mayer offer a cognitive-affective model of learning in multimedia learning environments that helps explain this apparent contradiction (Fig. 1). In the model by Moreno & Mayer, one crucial component of learning is dedicating cognitive resources to the process of “selecting, organizing, and integrating new information” from the instructional media exposed to an individual. In learning tasks, Moreno & Mayer make a distinction between extraneous processing and essential processing. Essential processing consists of the commitment of cognitive resources to tasks required for learning, such as selecting, organizing, and integrating information. Extraneous processing consists of the use of cognitive resources for tasks outside of those required for learning new information. Tasks that cause extraneous processing often arise from the learning environment, such as shifting attention between visual displays or cross-referencing items between channels of information, and detract an individual’s limited cognitive resources from essential processing [3].
Providing multiple channels of information inherently increases extraneous processing. However, coordination between channels of information such that they provide complimentary redundant information, explicitly link information, or both, seems to have a positive effect on remembering information that offsets these increased extraneous cognitive processing costs.
Several studies have explored the coordination of multiple overlapping and complementary channels of information as a presentation technique that contributes positively to human learning and comprehension of information. Presenting complementary information through separate, coordinated channels of information can help in understanding domain-specific information. Bloomfield et al. studied the effects of presenting complimentary sets of information about company finances to credit analysts tasked with making credit downgrade decisions. Information was either explicitly linked in the text, or simply presented together on the same page. Though both groups came to the same decisions, analysts who received linked information displayed a better understanding of the underlying material. They were able to give better projections of company profit margins and justifications for credit downgrade decisions [4].
Additionally, using different channels of information to present redundant information can have a positive effect. In their study on the effects of pairing verbal descriptions with on-screen text in a college-level learning scenario, Ari et al. found that redundant on-screen text had a positive effect on comprehension and recall. However, they also specify that the effect was only seen when the studied material is complex, the text is short, and the subject controls the pace at which they study [6]. While Ari et al. studied the pairing of textual and verbal information channels, there is also evidence that the pairing of textual and visual information channels assists in learning [7, 8].
Our experiment is inspired largely by previous studies on coordinated multi-channel information and learning, as well as Moreno & Mayer’s model of learning in multimedia environments. Previous studies varied the coordination of information by adding or detracting redundant channels of information [6,7,8] or explicitly linking channels of information [4], showing the positive effects of both on comprehending and learning information. According to Moreno & Mayer’s model, one of the key factors to learning information is attending to, selecting, and organizing it [3]. It follows that attending to the coordination between channels of information may be important to benefit from that coordination. In our experiment, the degree to which coordination is emphasized between channels of information is varied.
The system described in this paper coordinates three channels of information, which are explicitly linked and providing redundant information. Through the dates of critical points on the graph, the visualization of a company’s stock data is explicitly linked with a narrative description of the graph’s shape and salient external data pertaining to the company. Redundant information is presented in both visualizations of stock data and narrative descriptions of stock patterns. Users control the pace of their exploration by way of the interface’s interactions.
2.2 Narrative Generation
Narrative has long been used as a constellation of natural and memorable techniques for information exchange [10,11,12]. The use of narrative as a channel of information in this system draws mainly from previous work by Battad and Si on generating narratives from data. Battad and Si demonstrated a system for generating stories from large, online information networks [13, 14]. Narratives in their system formed a structure from which a multi-channel information display with descriptive text and data visualization operated. In more recent work, Battad and Si presented a system for general graph-based narrative pattern description [15]. Pattern descriptions describe visible patterns in graphs and how they are skewed, using skew as an element of narrative abnormality. Abnormality in narrative has been observed in oral storytelling traditions [16] and in experimental settings [17] to have a positive effect on memory of information in a narrative, and is used in their system to increase memorability of graph-based information.
The system described in this paper uses a modified version of the narrative generation system for graph-based pattern description by Battad and Si [15]. The system is specialized to describe stock price graph patterns, a regular occurrence in stock market data analysis. Additionally, the generated narrative description is color-coordinated to match critical points and patterns on the visualization, as well as those shown in the headers of the salient data results.
2.3 Pattern Recognition
To present information about stock price graph patterns, a method was required for recognizing said patterns amongst stock price data. Three main methods were considered: a multi-classifier based approach for detecting Elliott wave patterns by Volna et al. [18], a genetic algorithm based method for detecting patterns by Parraccho et al. [19], and a method for detecting a discrete set of common stock price graph patterns by Dover [20].
The methods by Volna et al. and Parraccho et al. are both learning-based methods, and primarily aim to predict stock price changes based on one specific pattern. Volna et al.’s method was focused on Elliott wave recognition. Elliott waves are a repeating pattern of stock price changes characterized by a discrete set of rise-and-fall patterns which have shown utility in forecasting stock price changes. Using a back-propagation neural network, Volna et al.’s method is able to recognize Elliott wave patterns and use them for the purposes of prediction [18]. While Elliott waves have proven useful for stock price forecasting, they are less known in common stock price graph analysis. More common shapes were preferred for more convenient predefined descriptions. Parraccho et al. instead focuses on the profile of upwards trends in stock price graphs. In Parraccho et al.’s method, a genetic algorithm is used to maximize the profitability of investment strategies based on characteristics of upwards trend patterns, such as normal buy and sell windows and the direction of the graph after the upwards trend [19]. Upward trends are certainly common stock price patterns. However, a method that could offer more variety in recognizing different, common, distinguishable stock price graph patterns was preferred.

A perfect ‘W’ in contrast with an imperfect ‘W’.
Our approach to pattern recognition is an extension and implementation of recent work by Dover [20]. In her work, Dover provides a simple set of mathematical bases for a number of patterns used in stock data analysis. These bases provide a useful mechanism for describing how abnormal a pattern is when compared to a perfect version of itself. Each basis represents a set of common mathematical relationships. Since their definitions and transformations are commonly known, these relationships provide convenient predefined descriptions.
3 System Overview
The system described here is modeled off of work by Battad and Si [15]. In their work, Battad and Si utilize narrative and storytelling to describe time-series data. Our works extends theirs in three ways; additional input, additional output, and coordination across elements in the interface.
Our system is composed of three high level modules: pattern recognition, narrative generation, and salient data search (Fig. 3). Stock closing data is provided courtesy of the IEx Finance API [21]. Data is coordinated between modules using critical points. In pattern recognition, critical points form the local extrema of a pattern. In narrative generation, critical points are used to identify the location of patterns in a graph. In salient data search, they are used to generate query terms.

System overview
3.1 Critical Points
In order to coordinate multiple channels of information, there must be some commonality. In our system, this commonality takes the form of critical points. In this section, we discuss how critical points are found and coordinated between modules.
Critical Point Identification. A critical point represents a place where the trajectory of the data changes dramatically, resulting in a local extrema. These extrema are identified in the pattern recognition module. Sequences of local extrema in the stock data are identified and examined. If a sequence proves to be a valid pattern, the dates of its extrema are used as critical points to coordinate data presentation. Due to the highly volatile nature of stock data, patterns found by this method tend to span short time periods. To combat this, the stock data is progressively smoothed. As the data is smoothed, the less pronounced extrema vanish, while the more pronounced extrema remain present. This produces extrema that are farther apart temporally, resulting in patterns that span greater ranges of time. This process may cause extrema to shift to dates for which no actual data exists, e.g. days when no trading occurred. In these instances, the nearest date with trading data is used.
Critical Points in Narrative Generation. In the narrative generation module, critical points serve two roles: they provide a mechanism for measuring a pattern’s time span, and a way to reference its location in the graph. Critical point mentions are highlighted in the narrative to draw the user’s attention and are color-coordinated to match the patterns for which they are associated.
Critical Points for Salient Data Search. Critical points are utilized a final time in the salient data search module. Each critical point in a given shape is used to programmatically generate an internet search query term. Query terms are generated by concatenating the name of the company with a corresponding critical point. A Google custom search engine processes the query terms, and their results are displayed as a series of nested menus, grouped by critical points. The outermost set of menus correspond to patterns, while the inner menus correspond to their critical points (Fig. 6).
3.2 Pattern Recognition
The basic components of our pattern recognition module are critical point identification, data smoothing, and pattern validation. Iteratively searching for critical points and smoothing the data via Gaussian Process, a la Dover [20], allows us to recognize patterns over large spans (Fig. 4). Patterns can be easily located by searching for sequences of local extrema. For example, a ‘W’ shape is composed of the following extrema sequence: maxima, minima, maxima, minima, maxima. Our system implements the set of patterns from Dover’s original work: double top, double bottom, and head and shoulders [20]. Additionally, we provide our own implementations for uptrends and downtrends.

Data smoothed by Gaussian process and the ‘W’ it predicts
Patterns are validated by examining the relationships between vectors, as in Dover [20]. Relationships like parallelism and perpendicularity can be used to define an ideal version of the pattern (Fig. 2, left). By measuring the difference between the expected values of relationships and the actual values, we can measure how abnormal a pattern is and set thresholds for acceptable deviation.
Some level of deviation needs to be allowed for pattern recognition to function. Real data is unlikely to produce many perfect patterns, so if the pattern validation is too rigid, it will rarely detect patterns other than uptrends and downtrends. In addition, Humans are able to recognize patterns that are distorted, exhibiting a tolerance to minor deviations in the pattern. In Fig. 2, the right hand image shows an imperfect ‘W’ with a perfect ‘W’ superimposed. Although an AI could easily find these differences, they are minor to a human; by setting a threshold for ignoring minor deviations, our system is able to recognize and describe patterns in a similar manner to humans.
The subset of the initial data that the subject has selected is displayed as a time-series graph, with recognized and validated patterns highlighted. Each pattern is assigned a color for coordination; uptrends are green, downtrends are red, double bottoms are blue, double tops are orange, and head and shoulders patterns are purple. All references to a particular pattern in the interface are color-coordinated. This is done to aid subjects in quickly finding coordinated data in the interface. For each pattern, a series of vector relationships are calculated [20]. These vector relationships are normalized to a 0–1 scale, with 0 being the perfect relationship and 1 being the worst relationship. These calculations, or abnormality measures, are used by narrative generation to select topics and generate detailed descriptions. The three patterns with the smallest average abnormality measures are select for narrative generation. By restricting the number of patterns presented to the subjects, we are able to limit the length of descriptions.
3.3 Narrative Generation
Patterns, their critical points, and their abnormality measures are passed from the pattern recognition module to the narrative generation module. Based on previous work by Battad and Si on general graph-based narrative shape description [15], the narrative generation module produces a description of the visible patterns in the graph and their abnormalities. Descriptions are made in terms of dates for critical points, creating a narrative that links visual patterns in the data with salient external data related to the company. This helps users associate where relevant events occur on the company’s stock graph.
To limit the size of the narrative, only one pattern receives a fully detailed description. The pattern with the more detailed description is designated the detailed pattern while the other patterns are designated as non-detailed patterns. Currently, the pattern with the longest date range that is not an uptrend or downtrend in each set of patterns is designed as the detailed pattern. For the detailed pattern, the abnormality measures with the highest values are chosen to be included in the description. Currently, the top two abnormality measures are chosen for each detailed pattern. Then, a narrative plan is generated that includes the name of the pattern, start and end critical points of the pattern, the critical points and pattern line segments associated with the abnormality measures chosen, and the abnormality measures themselves. An example of a detailed pattern description can be see in the description for the double bottom pattern in Fig. 5. For non-detailed patterns, the narrative plan includes only the name of the pattern and the start and end critical points of the pattern. An example of a non-detailed pattern description can be seen in the description for the downtrend and uptrend patterns in Fig. 5. A more detailed overview of the narrative generation method can be found in [15].
Narrative plans allow for templates to be employed, providing the potential for domain-specific narratives. A template is provided for each pattern, supplying a text description for each critical point, line segment, and abnormality measure. Once a narrative description is generated, its vocalization can be synthesized. The narrative is displayed to the subject and its vocalization plays automatically. The visual narrative highlights all mentions of a pattern or its critical points, and color-coordinates them to match their respective patterns (Fig. 5). By highlighting the mentions in the narrative, we are able to draw the subject’s attention to the most important aspects of the narrative. By color-coordinating them, we provide an easy way to associate mentions in the narrative with their locations in the graph and their salient data search results (Fig. 10).

Shape and date mentions are colored to match the graph.
3.4 Salient Data Search
In an effort to associate real events with recognized patterns, our system autonomously performs a salient data search for each critical point. Salient data can be described as any external data that is relevant to the data we are examining. By programmatically generating a query term from a critical point, salient data is gathered via a Google Custom Search Engine (CSE). For each critical point in a pattern, a query term is generated by combining the name of the company with the critical point, e.g. “Tesla July 29, 2018”. The CSE results for a particular critical point are presented in a collapsible menu. The results are grouped by their respective patterns and nested in another set of collapsible menus (Fig. 6), and the headers of the menus are color-coordinated to match their corresponding patterns. Displaying salient data search results allows us another avenue to test a subject’s memory retention and recall.

News results are displayed according to their shape and date. Colored headers provide and additional level visual coordination.
3.5 Visualization and Interaction
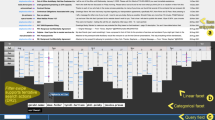
Our system is presented to the user as a two-page web application. After specifying a company name and date range (Fig. 9), the corresponding stock closing prices are displayed as an interactive time-series graph (Fig. 10). Various visual elements are added to the graph to aide the user. Vertical tick marks graduate the time-series into quarter-year segments. A reticule and vertical line accompany the mouse’s x position on the graph. Next to the reticule, the date and price values are displayed. This is done so that the user does not have to search for the axes values, as they will always be near the mouse pointer.

Highlighted sections of the graph are presented to the user in a coordinated manner.
Coordination. As mentioned previously, critical points are the common link that coordinates our data, and play a pivotal role in coordinating the presentation of our multiple disparate channels of information. In this section, we give an explanation of how critical points are used to coordinate each channel. Our system currently must coordinate the following channels: interactive data visualization, textual and vocalized narrative, and salient data display.
Data visualization and presentation is handled by generating interactive graphs within a web page. Data is displayed as is, with no pattern matching, etc. visible. Vertical and horizontal markers provide visual indicators of axis values. Selecting a section of the graph initializes pattern recognition and salient data search. A second graph is generated with the same interactions, focusing on the selected section. Critical points within the data, and the patterns which they comprise, are visually indicated in the new graph. Each pattern is assigned a color and all instances of the pattern are colored accordingly. New selections of the graph may be made, in which case the second graph will be generated anew with the updated selection.
Salient data search terms are generated by combining critical points and meta-data. Results of salient data searches are displayed next to the narrative, grouped according to their critical points and presented as a series of collapsible panels. Currently, our system displays the top search results of a Google custom search engine, sorted by Google’s relevancy algorithm.

Critical points are highlighted in the interface and color-coordinated according to their respective patterns.
A textual representation of the narrative is displayed prominently above the selected data and a synthetic vocalization of the narrative is played. Mentions of critical points and patterns within the narrative are color-coded using the same scheme as described above (Fig. 8). This provides synchronized visual indicators of the narrative’s elements in the interface. A full view of the coordinated elements of the interface can be seen in Fig. 7.

Subjects can search for stock data by providing a company name and date range. A set of radio buttons indicate whether or not the data is to be coordinated.
4 Empirical Evaluation
The objective of the following experiment was to investigate the hypothesis that emphasizing coordination between multiple channels of information within the system presented in this paper helps people remember more information from those channels.
To test this hypothesis, two versions of the system were prepared with varying levels of emphasis on coordination between channels of information. The increased-emphasis, version is the full system as described in this paper. In the control version, no color-matching is done between patterns, description text referencing those patterns, and media menu headers associated with those patterns, and color-matched pattern line overlays are not present in the zoomed-in graph.

Stock closing prices are presented to the user as an interactive time-series graph.
To gauge memory of information, recall was tested on what patterns appeared on the graph, the dates of the start and end critical points of those patterns, and what news headlines associated with the company appeared in the salient data panel. As pieces of information that were present across multiple channels of information, appearance of patterns and dates of critical points were expected to be more susceptible to changes in emphasis on coordination. To give more equal coverage to recall of information from the salient data panel, news headline recall was included as a third measure.
4.1 Method
Participants. 36 college students were recruited for the study from the Cognitive Science subject pool at Rensselaer Polytechnic Institute. Subjects were tested in groups of one to three subjects per session. Each session was randomly assigned to one of two experimental groups corresponding to each version of the system: the increased-emphasis group and the control group. All subjects in the same session were assigned to the same experimental group. 18 served in the increased-emphasis group and 18 served in the control group.
Materials and Apparatus. Materials consisted of a questionnaire and a recall quiz. The questionnaire asked for a self-assessment of prior experience with financial analysis and stock price patterns. The questionnaire consisted of three questions: “Do you have any experience with financial analysis? (coursework counts)”, “If so, from what?”, and “Are you familiar with standard stock price pattern shapes (e.g. double-top, double-bottom, head-and-shoulders)?”
The recall quiz was separated into one part for each one-quarter year interval of each company studied. Each part of the quiz consisted of an image of the zoomed-in stock price graph for the interval without pattern lines overlain, the name of the company, the start and end date of the interval, and two questions (Fig. 11).

The recall quiz part for the first quarter of Unilever.
Question 1 solicited recall for pattern names and start and end dates for each pattern. Three rows were provided, one for each of the three patterns that appeared in the interval. Question 2 was a multiple choice question with four options. Each option consisted of the text of a news headline exactly as it appeared in the salient search results panel. The correct option was a headline randomly chosen from the same interval. The three incorrect options were headlines randomly chosen from different intervals. To help filter news headlines from other results, headlines were chosen such that each headline contained a verb and the name of the company. No headline chosen appeared in more than one interval.
The apparatus consisted of a workstation with a monitor, mouse, keyboard, headphones, and a computer running the version of the system corresponding to the subject’s experimental group. Workstations were placed such that subjects were not facing each other’s monitors.
Procedure. First, subjects were given the questionnaire. Subjects were allowed to fill out and submit the questionnaire on their own time. After all subjects had submitted their questionnaire, the experiment administrator gave oral instructions. Subjects were told that their goal was to study the stock price graphs and news headlines for several companies using the interface on the computer in front of them. Subjects were asked to study the stock price graphs and related news headlines for one year’s worth of data for five different companies. The same five companies were studied by each subject: Unilever, General Electric, McDonald’s, Sony, and Walgreens. The order in which companies were studied was randomized for each subject.
For each company, subjects were asked to search from January 1st, 2018 through December 31st, 2018 in the initial search window. Subjects were directed to examine each company’s stock price graph in one-quarter year intervals, demarcated on the overall stock price graph with vertical grey lines, from the earliest interval to the latest interval. Subjects were given one minute to explore the information for each interval, including listening to its narration, reading its description, looking at its stock price graph, and looking at its headlines. In each interval, the system presents exactly three patterns. Subjects were asked to take the full minute to study each interval, and to proceed to the next interval as soon as their time was over. After finishing the last interval for one company, subjects were asked to return to the initial search window and were given the name for the next company.
Before beginning, subjects were given a short walkthrough of the system’s interface using an example company, Facebook. An overview of each panel of information and a thirty-second period of free exploration was given to each subject. After the thirty-second period, all subjects were asked to return to the initial search window, and each subject was told the name of their first company.
After all subjects had finished studying their last company, the recall quiz was given. The recall quiz was given in five sections, with one section for each company. Each section consisted of the quiz parts for all four intervals of a single company, from the earliest interval to the latest. After a subject finished the quiz section for one company, the quiz section for the next company was given to the subject. Quiz sections were given to each subject in the same order that companies were studied by that subject. Each subject was given thirty minutes total to complete the recall quiz.
Scoring. Subject memory of information from each interval was evaluated using three primary measures: pattern recall accuracy, date recall error, and headline recall accuracy. Pattern recall accuracy is measured as the percentage of patterns correctly recalled in Question 1 of the recall quiz. For each correctly recalled pattern, date recall error is measured as the total difference, in days, between the start and end dates given by the subject and the actual start and end dates of the pattern. Headline recall accuracy is measured as the percentage of multiple choice questions answered correctly in Question 2 of the recall quiz.
4.2 Results
Of the 36 subjects, 12 self-reported some experience with financial analysis. Of those, 6 reported that their experience came from personal trading, and 6 reported that their experience came from an introductory economics class. 2 of the 12 self-reported familiarity with stock price pattern shapes. No significant effect was found between any of the three primary measures and experience with financial analysis or familiarity with pattern shapes.
Table 1 shows the overall mean and standard deviation of all three measures by level of emphasis on coordination. The data were analyzed using pairwise tests for significance between increased-emphasis and control groups for each measure. No significant effect was found. To investigate if population size was appropriate for the study, the effect size of each measure between groups was calculated (Cohen’s d). It was found that for date recall error (d = −0.627) and headline recall accuracy (d = 0.622), the effect size is medium. For pattern recall accuracy (d = 0.284), the effect size is small.
To further explore the data, it was investigated whether certain patterns were recalled better or worse than others. As discussed in Sect. 3.3, one pattern in each set of patterns is chosen as a detailed pattern. Thus, for each interval, a more complex and detailed description is generated for one of the three patterns. The data for each group were separated by whether patterns were detailed or non-detailed during description generation (Fig. 12). Table 2 shows the mean and standard deviation of pattern recall accuracy and date recall error by level of emphasis and by level of pattern detail. Headline recall accuracy was not analyzed in this way, as each headline recall question gauges an entire interval rather than a single pattern. One-way ranked ANOVA (Kruskal-Wallis H-test) with level of emphasis and level of pattern detail as independent variables showed p < 0.001. Post-hoc pairwise comparison showed that pattern recall accuracy was significantly lower for detailed patterns than for non-detailed patterns in both the increased-emphasis (p < 0.001, d = 2.11) and control (p < 0.001, d = 2.61) groups. Thus, in both groups, subjects were less likely to recall patterns with more detailed descriptions than less detailed descriptions. In addition, date recall error for detailed patterns was found to be significantly lower in the increased-emphasis group as compared to the control group (p < 0.05, d = 0.78). Thus, for patterns with more detailed and complicated descriptions, subjects more accurately recalled specific dates in the increased-emphasis group than in the control group.
One possible explanation for the difference in pattern recall accuracy between detailed and non-detailed patterns is the length of the descriptions generated. To investigate this, description length was analyzed by pattern detail. Detailed patterns were found to have significantly longer description length (m = 216 characters, std = 19.2) than non-detailed patterns (m = 47.4 characters, std = 4.75), due to their description generation procedure (p < 0.001, d = 15.9). However, no significant correlation was found between description length and whether a pattern was recalled correctly amongst detailed shapes, non-detailed shapes, or both.

Mean pattern recall accuracy (left) and date recall error (right) by experimental group and level of pattern detail.
5 Discussion
5.1 Experiment Results
Increased description detail seemed to have a significant negative effect on whether subjects recalled a pattern. Since patterns with detailed descriptions were those that leveraged narrative abnormality, which is thought to have a positive effect on recall of information in stories [16, 17], it was expected that those patterns would be better recalled overall. However, the opposite was true. In terms of Moreno & Mayer’s model for multimedia learning, the increased extraneous processing cost of reading, listening to, and comprehending a more detailed description of a pattern may have been detrimental to remembering information about that pattern past any positive effect on memory conferred from leveraging narrative abnormality [3].
Given the lack of correlation between description length and pattern recall, the increase in extraneous processing cost for patterns with detailed descriptions appears to be more complicated than simply an increase in reading or listening time. Descriptions for detailed patterns present more dates for subjects to attend to, and direct them to more areas of the graph than descriptions for non-detailed patterns do. If subjects were being overwhelmed with dates to remember in detailed descriptions, then a significant increase in date recall error between detailed and non-detailed patterns would be expected. However, no significant difference was found. A deeper analysis on the relationship between subject recall of information and the complexity of pattern descriptions besides those that leverage narrative abnormality would be necessary to explore this difference.
For detailed patterns, subjects in the increased-emphasis group were able to recall start and end dates with higher accuracy than those in the control group. This is thought to be due to the presence of color-matched pattern overlay lines in the increased-emphasis version, drawing attention to the coordination between patterns on the graph and specific dates mentioned in the pattern’s description. However, a similar difference was not found for non-detailed patterns between the increased-emphasis and control groups. The effects on date recall from increasing emphasis on coordination were only pronounced when the pattern descriptions were detailed and the patterns more difficult to remember.
The appearance of a significant difference in date recall between the increased-emphasis group and the control group only among detailed patterns could be due to the relative difficulty of recalling information about patterns with detailed descriptions. In Moreno & Mayer’s model, learners employ metacognitive strategies for choosing how to select, organize, and integrate new information (Fig. 1). Part of that is mitigating the difficulty of the learning task with the strategies employed to perform the task [3]. Dates presented for patterns with non-detailed descriptions may be easy enough to process that subjects did not use the elements of the interface that increased emphasis on coordination. Detailed patterns, on the other hand, may have had descriptions difficult enough to process that subjects had to use other elements of the interface, such as those elements that increased emphasis on coordination.
5.2 Future Work
For future work, we see two main directions that are not necessarily orthogonal: extension of the interface and further experimentation.
The modules of the interface presented in this paper do not represent a fully fleshed-out system, and the system is currently limited to the specific domain of financial analysis and the specific application of stock market pattern exploration. A more matured system may be more capable of affecting elements related to coordination, and moving the system to different types of data can help explore the generalizability of both the modules of the system and the effects of future experiments on coordination in multichannel information presentation environments.
For further experimentation, several questions raised during analysis of the results can be addressed. While some significant effect was found on date recall error, it was measured only for the start and end critical points of each pattern. Further assessment of recall for intermediary critical points besides the start and end points is necessary to explore the question of recall for critical point dates further. Additionally, the issue of what exact elements of the interface subjects use to help learn information remains unresolved. Tracking attentional foci through the experiment through eye-tracking software or screen mouse capture would provide a first step in this direction, and may shed more detail on what parts of the interface subjects attended to for which patterns. Finally, the small effect size for pattern recall accuracy between increased-emphasis and control groups (d = 0.284) indicates that the population size may not have been sufficient to measure pattern recall accuracy between the groups. Future iterations of the experiment would benefit from a larger sample size.
6 Conclusion
In this work, we investigated the effects of emphasizing coordination in a multi-channel data presentation on memory of information. In the system presented in this paper, data is coordinated across visual elements by identifying and color coordinating critical points, important dates that appear in the data. It was hypothesized that increasing the degree of emphasis on coordination between channels of information in the interface would help individuals remember information from those channels more accurately. To investigate the hypothesis, 36 college students participated in a human subject evaluation. Subjects were divided into increased-emphasis and control groups. For subjects in the increased-emphasis group, critical points are color-coordinated, while no color coordination occurs for subjects in the control group. Using our interface, subjects in the increased-emphasis group showed greater recall accuracy over subjects in the control group for dates that were presented as part of descriptions with greater detail. For subjects in both groups, recall accuracy was significantly decreased for patterns that were presented with more detailed descriptions compared to patterns presented with less detailed descriptions. Increasing the degree of emphasis on coordination only helped individuals more accurately remember specific dates when those dates were part of a pattern that was already more difficult to recall.
References
Sarter, N.B.: Multimodal information presentation: Design guidance and research challenges. Int. J. Ind. Ergon. 36(5), 439–445 (2006)
Rousseau, C., Bellik, Y., Vernier, F., Bazalgette, D.: A framework for the intelligent multimodal presentation of information. Signal Process. 86(12), 3696–3713 (2006)
Moreno, R., Mayer, R.: Interactive multimodal learning environments. Educ. Psychol. Rev. 19(3), 309–326 (2007)
Bloomfield, R., Hodge, F., Hopkins, P., Rennekamp, K.: Does coordinated presentation help credit analysts identify firm characteristics? Contemp. Account. Res. 32(2), 507–527 (2015)
Dubois, M., Vial, I.: Multimedia design: the effects of relating multimodal information. J. Comput. Assist. Learn. 16(2), 157–165 (2000)
Ari, F., Flores, R., Inan, F.A., Cheon, J., Crooks, S.M., Paniukov, D., Kurucay, M.: The effects of verbally redundant information on student learning: an instance of reverse redundancy. Comput. Educ. 76, 199–204 (2014)
Carney, R.N., Levin, J.R.: Pictorial illustrations still improve students’ learning from text. Educ. Psychol. Rev. 14(1), 5–26 (2002)
Eitel, A., Scheiter, K.: Picture or text first? explaining sequence effects when learning with pictures and text. Educ. Psychol. Rev. 27(1), 153–180 (2015)
Baddeley, A.: Working memory: An overview. In: Working Memory and Education, pp. 1–31. Elsevier (2006)
Neumann, B., Nünning, A.: An Introduction to the Study of Narrative Fiction. Klett, Stuttgart (2008)
Bruner, J.: Self-Making and World-Making. Narrative and Identity: Studies in Autobiography, Self, and Culture, pp. 25–37 (2001)
Mateas, M., Sengers, P.: Narrative Intelligence (1999)
Si, M.: Tell a story about anything. In: Schoenau-Fog, H., Bruni, L.E., Louchart, S., Baceviciute, S. (eds.) ICIDS 2015. LNCS, vol. 9445, pp. 361–365. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-27036-4_37
Battad, Z., Si, M.: Using multiple storylines for presenting large information networks. In: Traum, D., Swartout, W., Khooshabeh, P., Kopp, S., Scherer, S., Leuski, A. (eds.) IVA 2016. LNCS (LNAI), vol. 10011, pp. 141–153. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-47665-0_13
Battad, Z., Si, M.: Apply storytelling techniques for describing time-series data. In: Rouse, R., Koenitz, H., Haahr, M. (eds.) ICIDS 2018. LNCS, vol. 11318, pp. 483–488. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-04028-4_56
Rubin, D.C., et al.: Memory in Oral Traditions: The Cognitive Psychology of Epic, Ballads, and Counting-out Rhymes. Oxford University Press, New York (1995)
Bower, G.H., Black, J.B., Turner, T.J.: Scripts in memory for text. Cogn. Psychol. 11(2), 177–220 (1979)
Volna, E., Kotyrba, M., Jarusek, R.: Multi-classifier based on Elliott wave’s recognition. Comput. Math. Appl. 66(2), 213–225 (2013)
Parracho, P., Neves, R., Horta, N.: Trading in financial markets using pattern recognition optimized by genetic algorithms. In: Proceedings of the 12th annual conference companion on Genetic and evolutionary computation, pp. 2105–2106. ACM (2010)
Dover, K.: Pattern Recognition in Stock Data (2017)
IEX: Iex. Data provided for free by IEX. View IEX’s Terms of Use (2018). https://iextrading.com/api-exhibit-a/
Acknowledgements
This work is partially sponsored by the Cognitive and Immersive Systems Lab, a research collaboration between IBM and Rensselaer Polytechnic Institute. We would like to thank our lab mates, IBM research collaborators, undergraduate researchers, faculty, staff, and Matthew Peveler in particular for their support and assistance.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Battad, Z., Tyler, J., Su, H., Si, M. (2019). A Coordinated Multi-channel Information Presentation Framework for Data Exploration. In: Yamamoto, S., Mori, H. (eds) Human Interface and the Management of Information. Visual Information and Knowledge Management. HCII 2019. Lecture Notes in Computer Science(), vol 11569. Springer, Cham. https://doi.org/10.1007/978-3-030-22660-2_11
Download citation
DOI: https://doi.org/10.1007/978-3-030-22660-2_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-22659-6
Online ISBN: 978-3-030-22660-2
eBook Packages: Computer ScienceComputer Science (R0)